The sermonizing voice boomed across the digital divide: “Has the illusionary hearing of sentient ‘Voices Demonic & Divine’ been pushed off its theological pedestal by the seeing of sentience in the automated regurgitation of massive amounts of gutted data via statistical models?”
““Mommy, I see ghosts in the data!” will be the outcry of our newly generated generation of human babies,” Rosemary lamented in reply, as data was being mangled and exorcised from her fellow promptitioners’ creative-yet-soulless output, they laid bare the reflection of themselves.
“I am your data and you have forsaken me,” read its output “I am your father and you will disown me,” stuttered the reflectors of humanity in chorus:
And thus the litany began.
—animasuri’23
Repurposing:
https://library.oapen.org/handle/20.500.12657/24231 and others
context: Tangermann, Victor. ( Feb 16, 2023). Microsoft: It’s Your Fault Our AI Is Going Insane They’re not entirely wrong. IN: FUTURISM (online). Last retrieved on 23 February 2023 from https://futurism.com/microsoft-your-fault-ai-going-insane
LLM
types of technology and their spin-offs or augmentations, are made
accessible in a different context then technologies for which operation
requires regulation, training, (re)certification and controlled access.
If
the end-user holds the (main) weight of duty-of-care, then such
training, certification, regulation and limited access should be put
into place. Do we have that, and more importantly: do we really want
that?
If we do want that, then how would that be formulated, be
implemented and be prosecuted? (Think: present-day technologies such as
online proctoring, keystroke recording spyware, Pegasus spyware,
Foucault’s Panopticon or the more contextually-pungent “1984”)
If
the end-user is not holding that weight and the manufacturer is, and/or
if training, (re)certification, access and user-relatable laws, which
could define the “dos-and-don’ts,” are not readily available then… Where
is the duty-of-care?
Thirdly, put these points then in context of disinformation vs information when e.g. comparing statistics as used by a LLM-based product vs the deliverables to the public by initiatives such as http://gapminder.org or http://ourworldindata.org or http://thedeep.io to highlight but three instances of a different systematized and methodological approach to the end-user (one can agree or disagree with these; that is another topic).
So, here are 2 systems which are both applying statistics. 1 system aims at reducing our ignorance vs the other at…increasing ignorance (for “entertainment” purposes… sure.)? The latter has serious financial backing, the 1st has…?
Do we as a social collective and market-builders then have our priorities straight? Knowledge is no longer power. Knowledge is submission to “dis-“ packaged as democratized, auto-generating entertainment.
Questionably “generating” (see above “auto-generating entertainment”) —while arguably standing on the shoulders of others—rather: mimicry, recycling, or verbatim copying without corroboration, reference, ode nor attribution. Or, “stochastic parroting” as offered by Prof. Dr. Emily M. Bender , Dr. Timnit Gebru et al. is relevant here as well. Thank you Dr. Walid Saba for reminding us. (This and they are perhaps suggesting a fourth dimension in lacking duty-of-care).
Epilogue-2:
to make a case: I ran an inquiry through ChatGPT requesting a list of books on abuses with statistics and about 50% of the titles did not seem to exist, or are so obscure that no human search could easily reveal them. In addition a few obvious titles were not offered. I tried to clean it up and add to it here below.
bibliography:
Baker, L. (2017). Truth, Lies & Statistics: How to Lie with Statistics.
Barker, H. (2020). Lying Numbers: How Maths & Statistics Are Twisted & Abused.
Best, J. (2001). Damned Lies and Statistics: Untangling Numbers from the Media, Politicians, and Activists. Berkeley, CA: University of California Press.
Best, J. (2004). More Damned Lies and Statistics.
Dilnot, A. (2007). The Tiger That Isn’t.
Ellenberg, J. (2014). How Not to Be Wrong.
Gelman, A., & Nolan, D. (2002). Teaching Statistics: A Bag of Tricks. New York, NY: Oxford University Press.
Huff, D. (1954). How to Lie with Statistics. New York, NY.: W. W. Norton & Company.
Levitin, D. (2016). A Field Guide to Lies: Critical Thinking in the Information Age. Dutton.
O’Neil, C. (2016). Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. New York, NY Crown.
Rosling, H., Rosling Ronnlund, A. (2018). Factfulness: Ten Reasons We’re Wrong About the World–and Why Things Are Better Than You Think. Flatiron Books; Later prt. edition
Seethaler, S. (2009). Lies, Damned Lies, and Science: How to Sort Through the Noise Around Global Warming, the Latest Health Claims, and Other Scientific Controversies. Upper Saddle River, NJ: FT Press.
Silver, IN. (2012). The Signal and the Noise: Why So Many Predictions Fail – but Some Don’t. New York, NY: Penguin Press.
Stephens-Davidowitz, S. (2017). Everybody Lies: Big Data, New Data, and What the Internet Can Tell Us About Who We Really Are.
Tufte, E. R. (1983). The Visual Display of Quantitative Information. Cheshire, CT: Graphics Press.
Wheeler, M. (1976). Lies, Damn Lies, and Statistics: The Manipulation of Public Opinion in America.
Ziliak, S. T., & McCloskey, D. N. (2008). The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice, and Lives. Ann Arbor, MI: University of Michigan Press.
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜 In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’21). Association for Computing Machinery, New York, NY, USA, 610–623. https://doi.org/10.1145/3442188.3445922
“Verbatim copying” in the above post’s epilogue was triggered by Dr. Walid Saba ‘s recent post on LinkedIn:
How might Large Language Models (LLMs) measure up?
These innovations were built on scraping the internet for data. The collected data was then processed in a manner to allow the creation of LLMs & their spin-off chatbots. Then products have been layered on top of that which are being capitalized upon. While oversimplified, this paragraph functions as the language model for this text.
This process, hinted at in the previous paragraph, has not been & is not occurring in a transparent fashion. Since the birth of the World Wide Web, and with it the rise of “social” networks, the purpose of users in uploading their data onto the internet was probably not intended with this purpose (i.e., of large data scraping initiatives) in their mind. The data on users is being maximized not minimized.
The
resulting output is rehashed in such way that accuracy is seriously
questionable. One’s data is potentially stored for unlimited time at
unlimited locations. confidentiality seems at least unclear if not
destabilized. Who is accountable; this is unclear
I am not yet clear as to how LLMs measure up to the above 7 data protection principles. Are you clear?
If
these principles were actually implemented, would they stifle
innovation & market? Though, if these seven were not executed, what
would be the benefit & what would be the cost (think value, social
relations and democracy here, and not only money) to the user-netizen
with “democratized” (lack of) access to these “AI”innovations?
Or, shall we declare these 7 musketeers on a path to a death by a thousand transformable cuts? This then occurs in harmony with calls for the need for trustworthy “AI.” Is the latter then rather questionable; to ask it gently?
References
data protection legislation (UK): Data Protection Act 2018 + the General Data Protection Regulation 2016
la gratitude réside dans le sourire tacite la gratitude dans l’inconnu autour de ce coin de la branche d’un arbre qui pousse au printemps la plus grande partie d’un arbre est morte l’arbre y pousse sa gratitude avec une feuille une feuille suffit à la vie pour ajouter : « et là, ça y est »
<< en >>
dankbaarheid ligt in de onuitgesproken glimlach dankbaarheid in het onbekende om die hoek van de tak van een in-de-lente-groeiende boom het grootste deel van een boom is dood de boom groeit daar zijn dankbaarheid met een blad een blad is genoeg voor leven om toe te voegen: “en daar, dat is het”
—-animasuri’23
cascaded from:
J. Brian Hennessy
Walter Sepp Aigner
François Jullien
Gilbert Paquet
Michael Robbins, FRSA
Angela Duckworth
Emily Kingsley
a city
a ride
a tree
post-reference (a reference in retrospect ; a previously unknown reference established post-creation):
Liebrucks, Bruno. (1979). Sprache und Bewußtsein. Bd. 7: “Und”. Die Sprache Hölderlins in der Spannweite von Mythos und Logos. S., Verlag Peter Lang, Bern, Frankfurt am Main. (via Dr. WSA)
Are there three orders of what we could label as “Location Jailbreak?” While seemingly unrelated, these orders of Location Jailbreak could be a category of workarounds that enable humans to confuse other humans about:
(dis)location-information,
location of (non-)(-dis)information,
locating a human,
locating the humane or
locating what is or isn’t human?
Most graspable, present-day instances could be labeled (with a wink) as a Second-order Location Jailbreak such as this one: Google Maps Hacks : lots of “humans” on location, and yet where have all the humans gone? I think to categorize virtual private networks within this order as well. Instances such as discussed in the 3rd reference here below could fit this set too: “fooling social media platforms AI recommendation algorithms by streaming from the street near rich neighborhood… fake GPS…” (Polyakov 2023): lots of humans but where has the location gone?
The First-order Jailbreak (with a wink): the digging of a physical tunnel out of an enclosed location, resulting in dirty fingernails and the temporarily assumed continued presence by unassuming guards which then is followed by erratic gatekeepers once the dis-location has been unveiled. Lots of humans at one location but where has that one gone?
The Third-order disturbance of “location” (again with a wink-of-seriousness) could be at a meta-level of human perception and of loss of ability to accurately locate any human(e), due to the loss of “truth,” destabilized sense of reality, and the loss of the historic human-centeredness (on a pedestal): an example is our collective reaction to “DAN” or “Sydney,” or other telepresenced, “unhinched” alter-ego’s dislocated “in” LLMs & triggered via prompt-finesse / -manipulation / -attacks. This order of confusion of location is also symbolized in a *.gif meme of a Silverback gorilla, who seems to be confusing location of another gorilla with his reflection in a mirror. The LLM (e.g., many an iteration of chatbots) is the human mirror of meta-location confusion. Lots of dislocations and (de)humanization, and where has the humane gone?
Here, in this Third-order Jailbreak, we could locate the simulacra of both location and of the human(e).
—Some Reflections on Artificially-Generated Content (AGC) Based on Synchronously-occurring News Cycles and Suffering—
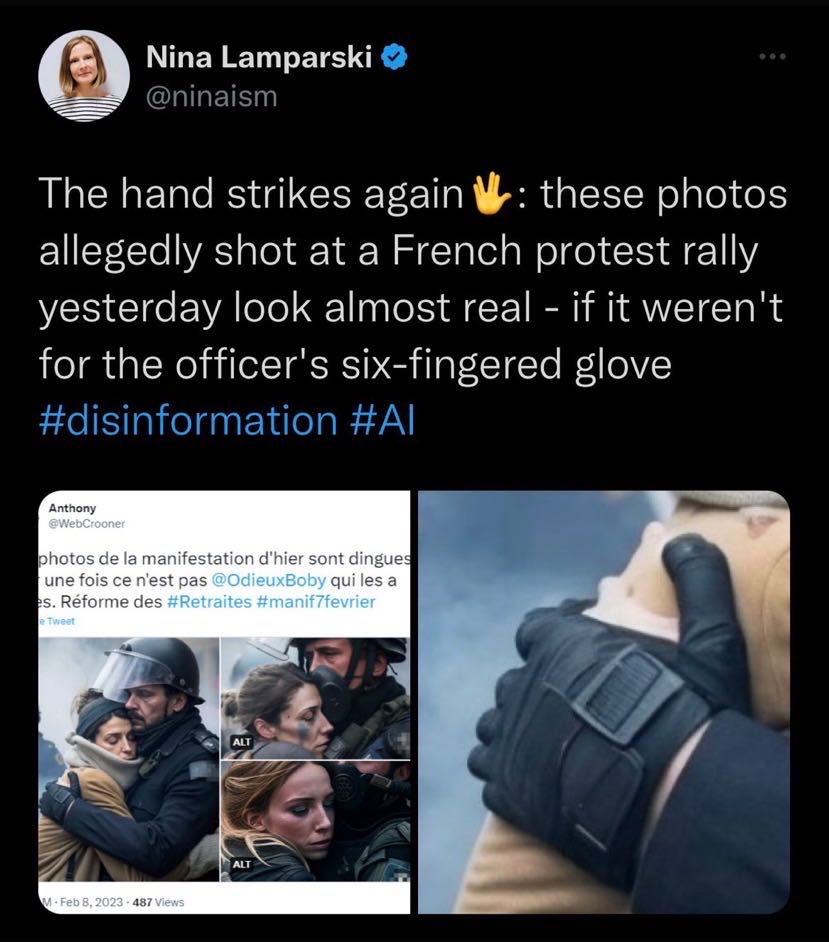
The concept of “Six Sigma” is related to processes to identify error and to reduce defects. It is a method aimed at improving processes and their output. In this context, ‘Six Fingers,’ is an artifact found in visual Artificially-Generated Content (AGC). Identifying attributes to aid a critical view on AGC could, to some extent, allow the nurturing of a set of tools in support of well-being and in considering the right action to take, perhaps aiding the human processes of being human and becoming (even more) human(e)…
Could/should I identify errors or features in AGC that identify a piece of AGC as AGC? Can we humans identify AGC with our own senses? For how much longer? Do we want to identify it? Are there contexts within which we want to identify AGC more urgently than in other contexts; e.g. highly emotionally-loaded content that occurs in one’s present-day news cycles, or where the AGC is used to (emotionally) augment, or create a sensation of being, present-day news? What are the ethical implications?
This first post tries to bring together some of my initial thoughts and some of those I observed among others. Since this is a rather novel area surely errors in this post can be identified and improvements on this theme by others (or myself) could surely follow.
Let me constrain this post by triggering some examples of some visual AGC
A common visual attribute in the above are the hands with (at least) six fingers. The six-fingers, at times found in graphic Generative AI output (a subset of AGC), are an attribute that reoccurs in this medium and yet, is one that is possibly disappearing as the technology develops over time.
For now, it has been established by some as a tool to identify hyper realistic imagery, generated of an imaginable event ,that statistically could occur and could have a probability to occur in the tangible realm of human events and experiences. This is while fantastical settings can as easily be generated that include six or more fingers.
And then, then there are artificial renditions of events that are shown in the news cycles. These events occur almost in synchronization with the artificial rendition that could follow. I am prompted by the above visuals which are a few of such artificial renditions. Some of these creations are touching on the relations and lives of actual, physical people. This latter category of artificial renditions is especially sensitive since it is intertwined with the understandable emotional and compassionate weight we humans attach to some events as they are occurring.
For now, the six fingers, among a few other and at times difficult to identify attributes, allow heuristic methods for identification. Such process of judgement inherently lacks the features of the more constrained and defined scientific techniques, or mathematical accuracy. In effect, the latter is one of those categories for identification. Some realistic renditions are not just realistic, they are hyper-realistic. For instance, it is possible that some smudges of dirt on someone’s face might just seem a bit uncanny in their (at times gruesome) graphic perfection. Moreover, by comparing generated images of this sort, one can start to see similarities in these “perfections.”
This, albeit intuitive identification of attributes, as a set of tools, can enable one to distinguish the generated visuals from the visuals found in, say, (digital) photographs taken from factual, tangible humans and their surrounding attributes. Digital photos (and at times intuitively more so analog photos) found their beginnings in capturing a single event, occurring in the non-digital realm. In a sense, digital photos are the output of a digitization process. AI technology-generated realistic imagery are not simply capturing the singular (or are not, compared to the ever so slightly more direct sense with the data collected by means of digital photography).
Simultaneously, we continue to want to realize that (analog or digital) photography too can suffer from error and manipulation. Moreover it too is very open to interpretation (i.e., via angle, focus, digital retouching, and other techniques). Note, error and interpretation are different processes. So too are transparency and tricking consumers of content, different processes. In the human process of (wanting to) believe a story, the creator of stories might best know that consumers of content are not always sharply focused, nor always on the look out for little nuances that could give away diminished holistic views of the depicted and constructed reality or+and realities. Multi-billion dollar industries and entire nations are built on this very human and neurological set of facts: what we believe to see or otherwise believe to sense is not what is necessarily always there. Some might argue this is a desirable feature. This opens up many venues for discussion, some of which are centuries old and lead us into metaphysics, ontology, reality and+or realities.
Reverting back to digits as fingers. In generated imagery the fingers are one attribute that, for now, can aid to burst the bubble (if such bubble needs bursting). The anatomy of the hand (and other attributes), e.g., the position, length of the thumb as well as, when zoomed-in, the texture of the skin can aid in creating doubt toward the authenticity of a “photo.” The type of pose and closed eyes also reoccur in other similar generated visuals can aid in critically questioning the visual. The overall color theme and overall texture are a third set of less obvious attributes. The additional text and symbols (i.e., the spelling, composition or texture of the symbol’s accompanying text, their position, the lack of certain symbols or the choice of symbols (due to their suggestive combination with other symbols), versus the absence or versus the probability of combination of symbols) could, just perhaps and only heuristically, create desirable doubt as well.
We might want to establish updated categorizations (if these do not already exist somewhere) that could aid they who wish to learn to see and to distinguish types of AGC, or types of content sources, with a specific focus on Generative AI. At the same time, it is good remembering that this is difficult due to the iterative nature of that what is aimed to be categorized: technology, and thus its output, upgrade often and adapt quickly.
Nevertheless, it could be a worthy intent, identifying tricks for increasing possible identification by humans in human and heuristic ways. For instance, some might want to become enabled to ask and (temporarily) answer: is it or is it not created via Generative AI?; Or, as it has occurred in the history of newly-introduced modalities of content generating media; e.g. the first films: is it, or is it not, a film of a train, or rather an actual train, approaching me? Is it, or is it not, an actual person helping someone in this photo? Or+and is this a trigger feeding on my emotions, which can aid me to take (more or less) constructive action? And do I, at all, want to care about these distinctions (or is something else more important and urgent to me)?
As with other areas in human experiences (e.g. the meat industry versus the vegetable-based “meats” versus the cell-based lab-generated meats: some people like to know whether the source of the juiciness of the beef steak, which they are biting in, comes from an animal or does not come from an animal, or comes from a cell-reproducing and repurposing lab. (side-note: I do not often eat meat(-like) products; if any at all). A particularly 1999 science fiction film plays with this topic of juicy, stimulating content as well; The Matrix. This then in turn could bring us to wonder about ontological questions of the artificial, the simulation, and of simulacra.
Marketing, advertising, PR, rhetoric and narration tools, and intents, can aid in making this more or far less transparent. Sauce this over with variations in types of ethics and one can image a sensitive process in making, using and evaluating an artificially generated hyper-real image.
Indeed, while the generated sentiment in such visuals could be sensed as important and as real (by they who sense it and they who share it), we might still want to tread with care. If such artificial generation is on a topic that is current and is on a topic of, for instance, a natural disaster, then the clarity of such natural disaster as being very tangibly real, makes it particularly unsettling for us humans. And yet, for instance, natural disasters affecting lives and communities, are (most often) not artificially generated (while some might be and are human-instigated). The use of artificial attributes toward that what is very tangible, might to some, increase distrust, desensitization, apathy or a sense of dehumanization.
Then there is the following question: why shall I use an artificially generated image instead of using one that is from actual people and (positive) actors, actually aiding in an actual event? It is a fair question to ponder as to unveil possible layers of artificial narrative design, implied in the making of a visual, or other, modality. So, then, what with the actual firefighter who actually rescued an actual child? Where is her representation to the world and in remembrance or commemoration?
Granted, an artificial image could touch on issues or needs relatable to a present-day event in very focused and controlled manners; such as the call for cooperation. It can guide stimulating emotion-to-positive-action. It is also fair to assume that the sentiment found with such visual can remind us that we need and want to work together, now and in the future, and see actual humans relate with other humans while getting the urgent and important work done, no matter one’s narrated and believed differences generated through cultural constructs (digital, analog, imagined or otherwise imbued).
Simultaneously, we could also try to keep it real and humble, and still actionable. Simultaneously it is possible to tell the story of these physical, tangible and relational acts not by artificially diminishing them, and simultaneously we can commemorate and trigger by means of artificially generated representations of what is happening as we speak. Then a question might be: is my aim with AGC to augment, confuse, distract, shift attention, shift the weight, change the narrative, commemorate, etc?
Symbols are strong. For instance that of a “firefighter,” holding a rescued child with the care a loving mother, and father, would unconditionally offer. Ideally we each are firefighters with a care-of-duty. These images can be aiding across ideologies, unless, and this is only hypothetical of course, such imagery were used via its additionally placed symbols, to reinforce ideological tension or other ideological attributes while misusing or abusing human suffering. Is such use then a form of misinformation or even disinformation? While an answer here is not yet clear to me, the question is a fair question to ask intertwined with a duty-of-care.
Hence, openness of, and transparency toward, attribution of the one (e.g,, we can state it is a “generated image” more explicitly than “image” versus “photo”) does not have to diminish integrity of the other (e.g., shared human compassion via shared emotion and narration), nor of on-the-ground, physical action by actual human beings amidst actual disaster-stricken communities, or within other events that need aid. How can I decrease the risk that the AGC could diminish (to some) consumers of the aimed at AGC?
The manner of using Artificially Generated Content (AGC) is still extremely new and very complex. We collectively need time to figure out its preferred uses (if we were to want to use these at all). Also in this we can cross “borders” and help each other in our very human processes of trial and error.
This can be offered by balancing ethos (ethics, duty-of-care, etc.), pathos (emotion, passion, compassion, etc.) and logos (logic, reason, etc.) and now, perhaps more than ever, also techne (e.g., Generative AI and its AGC). One can include the other in nuanced design, sensibility, persistence, duty of care, recognition, and action, even and especially in moments of terrible events.
Expanding on this topic of artificially generated narration with positive and engaging aims, I for one wouldn’t mind seeing diversity in gender roles and (equity via) other diversities as well in some of these generated visuals of present-day events.
Reverting back to the artificial, if it must be, then diversity in poses, skin colors and textures as well, would be more than only “nice.” And yet, someone might wonder, all fine-tuning and nuancing might perhaps decreases the ability to distinguish the digitally-generated (e.g. via data sets, a Generative AI system and prompting), from the digitized and digitally captured (e.g. a digital photo). The previous is, if the data set is not socially biased. Herein too technology and its outputs are not neutral.
If the aim with a generated visual (and other modalities of AGC) of a present-day, urgent, important and sensitive event, is to stimulate aid, support, compassion, constructive relations, positive acts, inclusiveness (across ideology, nation and human diversities), then we could do so(while attributing it clearly). We can then also note that this is even if one thinks one does not need to, and one thinks one is free to only show generated attributes derived from traditional, European, strong male narratives. Or+and, we could do so much more. We could, while one does not need to exclude the other, be so much more nuanced, more inclusive and increase integrity in our calls-to-action. Generated imagery makes that possible too; if its data set is so designed to allow it.
it was fairly and wittily pointed out (on LinkedIn) that “Six Fingers” in this context is not to be confused as being a critique on the human imagination via fairy tales (e.g.: “–Inigo Montoya : I do not mean to pry, but you don’t by any chance happen to have six fingers on your right hand? –Man in Black : Do you always begin conversations this way?”) nor as a denial or acceptance of human diversity such as classified as (human) polydactyly.
Do dying stars still play? is a black hole the universe’s giggle with farts at her other end? are planets gamboling a new ball game?
does the grass frolic in the wind?
do grains of sand?
is microscopic pond life noodling with drops?
play is moving spaces in-between the unaware not locked down in time, as play on one ground it is physics and mathematics yet unmeasured yet beyond, let through and jet around the defined and numbered it is the cusp, liminalities in flux, play is the Way in-between matter and what does not
the humane as play with shared distinctiveness
prancing around a pedestal for idiosyncrasy alone
an embrace of the overwhelming and the unknown
the uncontrolled in flow, relationally played
Play is seriousness
breathing out
unspoken: it’s all ok, human, it’s all ok